En general siempre pensamos que el proceso de digitalización es algo de lo que nos vamos a hacer cargo nosotros mismos, pero a veces, por las circunstancias que sean, trabajamos con digitalizaciones en PDF hechas por otros que son de dudosa calidad. En otros casos, las condiciones de entrada de la información no son todo lo óptimas que nos gustarían: por ejemplo, porque fuimos a una biblioteca a tomar las imágenes y no había buena iluminación o no podíamos abrir demasiado el libro, y por lo tanto las imágenes nos quedaron torcidas.

En general, el mejor consejo es siempre tomar una buena fotografía o hacer un buen escaneado la primera vez, lo que nos ahorra trabajo posteriormente. Pero como no siempre es posible, escribimos este post para solucionar algunos de esos problemas. Vamos a ir paso por paso trabajando con distintas variables; si ustedes ya tienen las imágenes y no necesitan extraerlo del PDF lo ideal sería que pasen al ScanTailor directamente. Los siguientes pasos están presuponiendo que después de terminar de extraer las imágenes vamos a trabajar con el ScanTailor, que requiere imágenes en formato JPG para trabajar. Otra cosa importante a tener en cuenta es que si tenemos una sola o pocas imágenes quizás convenga trabajar con el GIMP directamente. Acá estamos suponiendo que vamos a trabajar con un lote importante de imágenes que no escaneamos nosotros.
Para otras opciones de corrección de imágenes de un PDF (como rotar imágenes en un PDF o intercalar imágenes faltantes), lo mejor es utilizar la utilidad de PDFShuffler (en Linux) o el PDFSam en Windows y Linux.
Primero: ¿cómo extraigo las imágenes de un PDF?
En Linux esta operación es bastante simple (por eso es que recomendamos siempre usar Linux!, ya que nos ahorra un montón de procesos que en Windows son más trabajosos), lo único que tenemos que hacer es abrir una terminal y utilizar el comando pdfimages con sus opciones (recuerden que si no sabemos las opciones siempre podemos hacer man pdfimages y acceder al manual de uso).
Otras opciones con interfaz gráfica -tanto en Linux como en Windows- es usar el GIMP (estas instrucciones valen también para otras opciones privativas, como el Photoshop). Para ello lo único que tenemos que hacer es abrir el programa, ir a «Archivo – Abrir» y seleccionar nuestro PDF. Ahí el GIMP nos va a dar la opción de «Importar archivo» y seleccionamos «Abrir páginas como imágenes» (y no como capas).
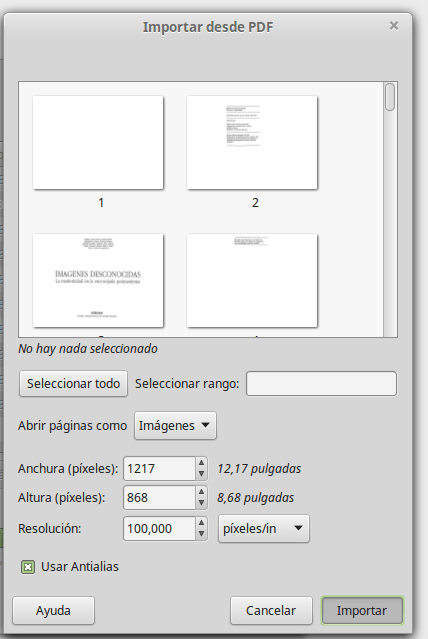
Esto lo que nos va a hacer es abrirnos cada una de las páginas como imágenes, y después tendremos que salvar cada una de las imágenes respectivas con el archivo de imagen que deseemos (jpg, tiff, etc.). Si vamos a trabajar luego con el ScanTailor, lo más lógico sería que las guardemos todas como JPG.
Obviamente, esta opción es la más práctica desde la perspectiva de un usuario que no está acostumbrado a trabajar con una interfaz gráfica, pero también hay que tener en cuenta que si el PDF contiene muchas páginas o es muy pesado el programa se nos puede trabar. Por lo tanto, es recomendable que tengamos esto en cuenta a la hora de trabajar con el PDF.
Otra opción es utilizar una utilidad en línea como el PDF Extractor o el iLovePDF, que funciona bastante mejor que el PDF Extractor y además tiene otras utilidades.
Por supuesto, cada método tiene sus ventajas y desventajas, por ejemplo, en el caso del pdfimages lo que voy a tener es quizás una curva de aprendizaje (si nunca usé una terminal), y además en general el formato de archivo que me devuelve después de extraer las imágenes no es un JPG sino un PBM (portable bitmap), que en general es el formato temporal que la mayoría de los programas de digitalización utilizan para guardar las imágenes escaneadas a un PDF, por lo que voy a necesitar convertir estas imágenes. Corrección del 2-8-2018: es posible obtener un JPG, hagan caso a lo que digo y usen el man pdfimages en vez de decir que lo usen y no usarlo, como hice acá, claramente.
En el caso del GIMP (o similares), la ventaja es que ya voy a obtener un JPG sin necesidad de convertirlo nuevamente (siempre y cuando lo guarde como JPG). Las utilidades en líneas como el PDF Extractor o el iLovePDF pueden tener problemas tales como aceptar solamente un tamaño de archivos determinado, limitar la cantidad de archivos que se pueden subir o tener una tasa de subida/descarga muy lenta (algo particularmente importante si nuestra conexión a Internet no es muy buena), entre otras.
Segundo: ¿cómo convierto otros formatos de archivos de imagen a JPG?
Nuevamente acá vemos las funcionalidades de Linux, ya que esto nos lleva un solo comando: el convert, que nos permite convertir nuestras imágenes con formato PBM en JPG de una manera muy simple. Si tenemos varios archivos que necesitamos convertir lo mejor es hacer un pequeño loop que tenga esta apariencia (parados desde la terminal en nuestra carpeta donde están los archivos, por supuesto):
for file in *.pbm; do convert $file jpg/${file%%.*}.jpg; done
Esto lo que va a hacer es convertir todas las imágenes en formato PBM a JPG (o de cualquier otro formato de imagen a JPG).
Si utilizamos el GIMP o el iLovePDF no es necesario que hagamos este paso. Pero supongamos que por la razón que sea tenemos un formato de imagen medio extraño que necesitamos pasar a JPG, la forma más fácil de hacerlo es nuevamente abriendo el GIMP y exportando las imágenes a JPG y ahí seleccionamos el formato de imagen que corresponda.

Tercero: trabajando con el ScanTailor
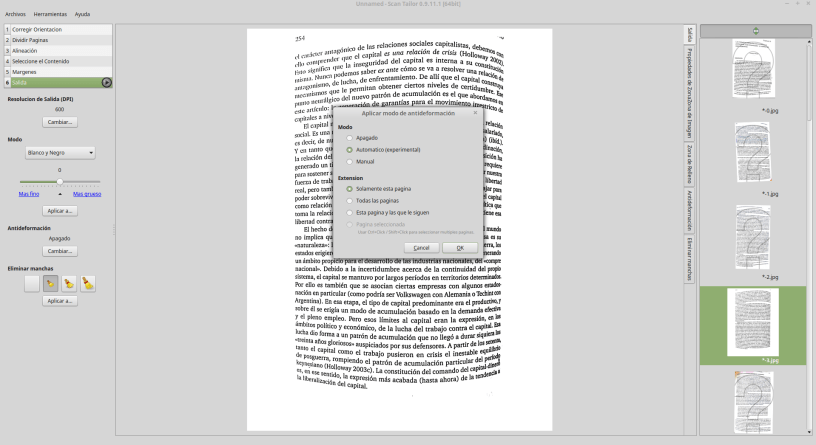
Ya hemos descripto el ScanTailor y hecho algún que otro tutorial, pero acá es donde nuevamente el ScanTailor vuelve a mostrar todo su poder como herramienta de procesamiento. En la primera foto que les pasé, pueden ver cómo quedó después de pasarla por el ScanTailor:

Por supuesto, esta imagen nunca nos va a quedar perfecta ya que nuestra entrada era de muy mala calidad, pero podemos acercanos a resultados mucho más aceptables que los que teníamos originalmente. Para obtener esta imagen utilizamos la opción «Antideformación» del ScanTailor en el paso 6 de Salida.
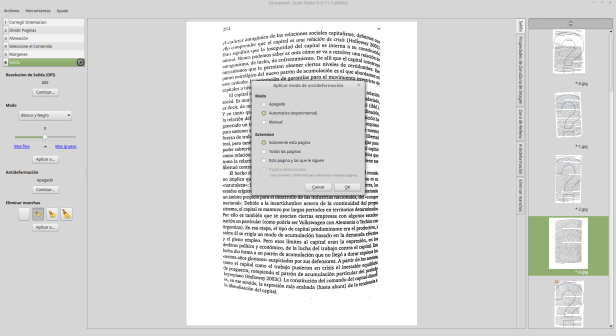
Nuevamente, hay que tener en cuenta los beneficios y desventajas de este tipo de operaciones. En general la herramienta «antideformación» funciona muy bien cuando la deformación es muy evidente como en este caso, y bastante peor cuando se trata de deformaciones más sutiles. Por eso insistimos en que siempre lo mejor es escaner bien a la primera para olvidarse de esots problemas. En este caso, siendo que el original estaba tan mal, la antideformación hizo un muy buen trabajo de corrección.
Otras opciones que me parece bien mencionar es que dependiendo para qué vayamos a usar las imágenes, también podemos jugar con las opciones del ScanTailor. Por ejemplo, una de las imágenes con las que yo necesitaba trabajar era para hacerle OCR (reconocimiento óptico de caracteres) y luego corregir el texto. Entonces, no me interesaba por ejemplo conservar los dibujos y gráficas que tenían las imágenes ni tampoco los números de páginas, por lo que en el paso de «Seleccionar contenido» corté esa información de manera tal que no me apareciera luego en mi imagen de salida (y por lo tanto en el OCR):

Y en el paso de salida, con la opción de «Zona de relleno», dibujé un cuadro que me eliminara el dibujo que aparecía al costado, de modo tal que después no interfiriera con el OCR, aportándome información que no me interesaba:

En fin, como siempre sostenemos en este blog, muchas de las herramientas que vamos a utilizar también dependen de qué es lo que necesitemos hacer, para qué y cómo. Lo fundamental es saber las herramientas que existen y en función de eso ser capaces de decidir cuál vamos a utilizar.

Es norma trabajar con imágenes en formato TIF al extraer del PDF para editar en Scantailor u otro programa para evitar o minimizar la perdida de calidad, por ej. la aparición de artefactos que son usuales en JPG por el proceso de compresión.
Saludos
Me gustaMe gusta
En realidad no tiene nada que ver. Cuando estás tomando imágenes con una cámara digital compacta, las tomás en JPG y el ScanTailor trabaja con eso y después las convierte en TIFF (es decir, que los artefactos en el JPG en ese caso se mantienen y son inevitables, la única forma de evitar algunos de ellos es trabajando con el RAW). Si las imágenes originales son malas por más que las extraigas en TIF el problema se mantiene. Saludos!
Me gustaMe gusta