
Ayer Mariana Fossatti publicó en Ártica un muy buen post sobre el tratamiento automatizado de textos. En la lista encuentran un montón de herramientas útiles, desde programas para hacer OCR (Reconocimiento Óptico de Caracteres), hasta otras listas que nos llevan a proyectos como el de Tabula PDF, un proyecto que tiene como uno de sus creadores al argentino Manuel Aristarán y que encaró nada más y nada menos que el vérselas con los PDFs y las tablas.
Desde el taller de digitalización tenemos una lista de «herramientas oficiales» para digitalizar que les damos todos los años a los estudiantes. La primera vez que dimos el taller tuvimos bastantes problemas con las compatibilidades entre Windows y Linux, por lo que este año decidimos dar herramientas que solamente funcionaran en AMBOS sistemas operativos. La realidad es que para trabajar con procesos masivos de edición de imágenes o de extracción de texto sigue siendo mucho mejor trabajar directamente con Linux, pero para muchos la migración sigue siendo un proceso difícil. Lo cierto es que hay procesos que en Windows requieren la instalación de un montón de utilidades, mientras que en Linux se hacen con una simple orden en la línea de comandos.
Ahora bien, en el taller no nos metemos para nada con el procesamiento automatizado de textos, que en realidad es el próximo paso «natural» una vez que ya conseguimos digitalizar nuestras imágenes. Por suerte, en esta vida no hace falta que un solo grupo se haga cargo de todo, y este año hubo un curso extensión en la Facultad de Filosofía y Letras de la UBA sobre «Herramientas computacionales para el procesamiento automático de textos». En su sitio web pueden acceder al listado de las herramientas con las que estuvieron trabajando, recursos, clases, ejercicios, materiales y más.
¿Es muy difícil hacer procesamiento automático de textos? ¿Qué necesito? Como difícil, difícil, es escalar el K2. Pero es posible hacer cierto procesamiento sin necesidad de grandes herramientas ni conocimientos, aunque es indispensable saber algo de cómo manejar una línea de comandos y entender un poco la sintaxis de las órdenes que vamos a ejecutar.
Algunas aplicaciones para entender la importancia de estas herramientas
Ahora, las preguntas que surgen son ¿por qué es importante el procesamiento automatizado de textos? y ¿qué puedo conseguir con eso? Hay algunas respuestas en el post de Ártica, pero me gustaría añadir otras ideas.
En la actualidad es muy probable que los lectores no-humanos superen con mucho a nuestros lectores humanos. Algunos de los usos más evidentes son los web crawlers, pero también proyectos que utilicen algún tipo de aplicación de los «n-gramas«, como el reconocimiento óptico de caracteres. El proyecto más ambicioso de este tipo es el Google N-Gram Viewer, que nos permite hacer una búsqueda entre los libros digitalizados por Google de distintos tipos de palabras para analizar apariciones de frecuencia (y también descargar su set de datos). Veamos por ejemplo esta búsqueda rápida que hice entre los términos «mapuche», «mapuches» y «araucanos»:
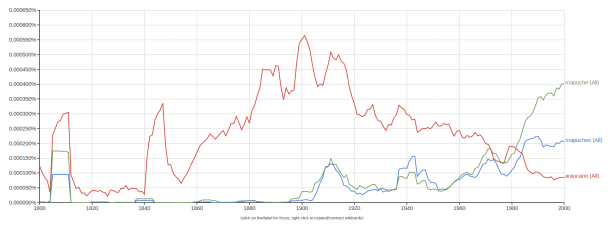
A partir de este gráfico se pueden hacer un montón de inferencias: es probable que la entrada en vigor de algún instrumento internacional hiciera que el término «araucano» (despectivo para los mapuche) empezara a caer en desuso, etc. No es mi intención meterme a hacer un análisis, simplemente mostrar estas herramientas y la clase de usos que se pueden aplicar.
En Argentina, quienes más se encuentran trabajando en este tipo de cruces entre la aplicación de herramientas computacionales para el procesamiento de lenguaje natural es el LIAA, el Laboratorio de Inteligencia Artificial Aplicada. Hace poco Edgar Altszyler (uno de los miembros del LIAA) estuvo en el Hack/Hackers presentando dos charlas sobre el sesgo de género en Hollywood a partir del análisis de los subtítulos de las películas y sobre las tendencias culturales que se pueden encontrar a partir del análisis automatizado de textos (y por suerte no estuvo en esta charla de la Ekoparty donde mostraron cómo hacer un ataque informático a través de los subtítulos).
En definitiva, ¿por qué es tan importante la aplicación de este tipo de herramientas computacionales sobre los textos? Porque las computadoras son muy eficientes para contar. Si nosotros tuviéramos que contar palabra por palabra y hacer análisis de apariciones tardaríamos años, mientras que una computadora lo puede hacer de una manera mucho más práctica de lo que podríamos hacer nosotros y sobre un enorme cuerpo de texto. A partir de esa información se pueden hacer análisis de tendencias, entre otros. Por ejemplo, este trabajo del Berkman Klein Center hace un análisis de las redes sociales, la propaganda y las elecciones 2016 en Estados Unidos, a partir de la utilización de herramientas como las que mencionamos.
¿Y por casa cómo andamos?
Desde el modesto espacio de este blog, también trabajamos con algunas herramientas de procesamiento automático de textos. Comentamos algunas de estas experiencias en la ponencia «Digitalización con escáneres «Do It Yourself» y scraping de textos para construir una base de datos del dominio público en Argentina«, que presentamos con Diego de la Hera en el I Congreso de Digitalización en el Museo del Cabildo en el 2016. Nosotros venimos trabajando en construir una base de datos sobre los autores y artistas que se encuentran en el dominio público (es decir, libres de copyright), en Dominio Público de Argentina. Este es un proyecto del que ya hemos hablado en el blog, contando la experiencia del sitio Autores.Uy.
Para armar este proyecto con un mínimo de seriedad necesitamos algo fundamental: fuentes bibliográficas que nos digan quiénes son los autores, dónde y cuándo nacieron, en qué género se especializaban, cuándo fallecieron (si es que fallecieron), etcétera. Este tipo de fuentes son desde diccionarios biográficos hasta antologías de artistas. A partir de los campos que tenemos construidos para nuestra base de datos, volcamos esa información en la base.
Cargarlos manualmente es una tarea titánica: existen muchas fuentes, muchas disciplinas y muchos autores. El problema es que las fuentes son todas distintas entre sí y no existe ningún denominador común. Algunas, las fuentes más antiguas, tienen la característica de presentar a los autores biografiados de maneras tan exóticas como esta:

Este es un ejemplo, pero la forma en que está organizada la información en esa fuente es poco estructurada y en general es muy difícil encontrar dónde nació un escritor, por ejemplo, sin hacer una lectura detallada de la fuente. Pero hay otras fuentes como esta:

Aquí la información está bastante estructurada y aunque hay datos que no nos provee (por ejemplo, la fecha de nacimiento), nuestro objetivo en esta primera instancia no es cargar información que la fuente no nos provee, sino poblar la base de datos. A mayor cantidad de fuentes con las que podamos trabajar de manera automática, más fácil es el proceso de poblar la base de datos (que, recordemos, no deja de ser una tabla). En general, el primer paso es hacer un buen análisis de la fuente con la que queremos trabajar. Para nuestra base de datos, donde tenemos campos como disciplina (ej., Escritura) y subdisciplina (ej., Narrativa), sirve mucho saber que estamos trabajando con una fuente llamada «¿Quiénes son los escritores de la SADE?». Listo, ya sabemos que ese es un campo que no necesitamos extraer de ninguna manera de la fuente porque todos pertenecen a la disciplina «Escritura». Pero también, hacer un buen análisis nos permite saber de entrada la complejidad de la tarea y qué herramientas vamos a necesitar.
De una manera más esquemática, los pasos que seguimos para trabajar con las fuentes son estos:

El OCR es el reconocimiento óptico de los caracteres, la «extracción» es el paso de procesar automáticamente el texto y volcarlo a una planilla (o más propiamente, un archivo separado por comas o CSV, commas separated values) y la integración es el análisis que hacemos entre los datos extraídos de nuestra fuente y la base de datos ya existente (ya que pueden haber casos de homonimia de autores, autores que ya se cargaron previamente con otra fuente, entre otros). El código fuente del integrador está disponible en el repositorio Github del proyecto.
En general, utilizamos algo llamado «expresiones regulares» (o regex, por sus siglas en inglés) para buscar patrones consistentes en la fuente de datos. Esto es lo que vamos a volcar en la base de datos. En nuestra expresión gráfica, una vez que obtenemos el OCR lo que hacemos es esto:

En algunos casos, es más fácil de obtener la información que en otros.
Por ejemplo, para nuestra foto de más arriba (el diccionario de escritores de la SADE), utilizamos simplemente sed y grep para pasar toda esa información a una planilla. ¿Qué elementos utilizamos para armar una planilla? Por ejemplo, sabemos que entre autor y autor está siempre la palabra SADE (con algunas variantes productos del OCR). Entonces, le pedimos a la línea de comandos que buscara «SADE» y todas sus variantes y la reemplazara por un salto de línea, lo que nos permite que eso después sea convertido en una fila separada en nuestro archivo CSV. Otra cosa que sabemos es que siempre tiene expresiones que se mantienen regulares, como por ejemplo «Género en que se expresa:» o «Seccional:» o «Publicaciones:». Tenemos forma de ir borrando todas esas expresiones o ir reemplazándolas por comas (recuerden que el CSV es un archivo «comma separated values», por lo que eso nos va a dar como resultados columnas distintas para cada información). Luego de repetir una y otra veces operaciones similares, lo que obtenemos es algo como esto:
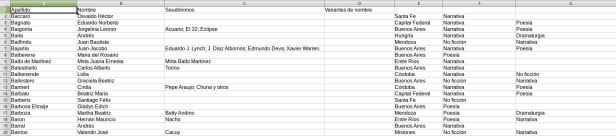
Luego ya podemos ir al paso final de la «integración», donde vamos a hacer cosas como asignarle sexo a los autores (si son hombre o mujer), entre otros aspectos. Esto lo podemos hacer con muchas fuentes, simplemente mostramos esta como ejemplo. Algunas fuentes tendrán otras características y complejidades, pero en general mientras la información esté estructurada, es posible trabajar con ella.
¿Qué tan confiable es el OCR (y el procesamiento automático)?
El motor de OCR de Tesseract nos ofrece dos informaciones muy valiosas: una es un «índice de confianza» de cada palabra. Esto es un valor que Tesseract nos da y nos dice con qué confianza reconoció una palabra determinada. Lo otro que nos da Tesseract es el archivo hOCR, que nos indica el valor posicional de cada bloque de texto. En un ejemplo:

Con estos dos valores yo puedo saber exactamente dónde está el error y corregirlo si es necesario. Pero, además, tengo otras formas de controlar (en el caso de una fuente, por ejemplo): los listados alfabéticos. Este tipo de materiales tienen un orden alfabético ya prestablecido que me permite saber que Geller aparece antes que Genovese, y que si por alguna razón yo tengo antes Genovese hay algo que está andando mal.
En cuanto al procesamiento automático de texto, pasa exactamente lo mismo: existen mecanismos para darnos cuenta si perdimos información valiosa. En el caso de nuestra fuente de «Quiénes son los escritores de la SADE», una forma de comprobar que tengamos todos los autores al final de todo el procesamiento es utilizando el índice de autores que trae el libro, ya que deberían coincidir los totales. Si no coinciden, podemos utilizar las herramientas de diff para comparar entre los dos archivos (una herramienta muy útil, por cierto), que también se puede usar online.
Por supuesto, cabe destacar además que (al menos en nuestro caso) siempre hay una instancia de lectura no automatizada, es decir, hecha por un humano. Lo importante es entender que todas estas herramientas, aunque a veces tengan curvas de aprendizaje un poco altas, nos ayudan después a hacer el trabajo de una manera más rápida. Por ejemplo, en un día trabajando ocho horas una persona puede cargar 100 autores en la base de datos, mientras que aplicando herramientas de análisis automático de texto, se pueden obtener más de 1500 autores para cargarlos de manera automática (como es el caso de la planilla de la SADE, que aún no está cargada en la base de datos). Esto es una forma de optimizar el tiempo y dedicarnos a hacer otras cosas que nos gusten más, como análisis que expliquen los datos que obtenemos.
