Este mes estuvimos terminando de armar el proyecto de digitalización de la revista Cuadernos del Sur, una revista de economía, sociedad y política desde una perspectiva marxista que se editó de 1985 a 2005. Para entender mejor la importancia de la revista, pueden leer las palabras preliminares de Eduardo Lucita, uno de sus directores.
Acá no nos vamos a detener tanto en el contenido de la revista, sino que vamos a aclarar cómo resolvimos algunas de las cuestiones más «técnicas», que sabemos que pueden ser de interés para algunos de los que cursaron el taller de digitalización o que simplemente están interesados en disponibilizar material y no cuentan con un montón de recursos. Para todo este trabajo usamos las siguientes utilidades, que ya hemos mencionado algunas veces en este blog: el escáner de libros «Do It Yourself», modelo Archivista; PiScan y marker-crop para captura y pre-proceso de las imágenes; The GIMP para la edición y manipulación de algunas imágenes (principalmente las tapas); ScanTailor para el post-proceso de las imágenes; gImageReader + Tesseract para el reconocimiento óptico de caracteres; algunas librerías de Linux como tiff2pdf y WordPress para la disponibilización del material.
En otro momento quizás conversemos sobre cómo armar las tapas de los libros a color o cómo hacer EPUBs, pero por lo pronto nos vamos a concentrar en estos tres puntos:
- ¿cómo hacer una separata de artículos (o índice analítico) de manera simple?;
- ¿cómo mejorar la tipografía original de un libro?;
- ¿cómo armar un índice de autores como este?
1. Separata de artículos: varias maneras
Hay varias maneras de armar separatas de artículos (también conocido como índice analítico). Para los que no saben qué es una separata, es básicamente lo que se puede ver en cada número de la Cuadernos y que nos permite acceder manera individual a cada artículo, sin necesidad de descargarnos toda la revista completa. Suele ser muy práctico cuando queremos revisar un solo artículo y no el número entero.
Para hacer la separata, se pueden utilizar algunas utilidades como el PDF Shuffler (en Windows es el PDFSam), que permiten mezclar PDFs, seleccionar páginas específicas e imprimir un nuevo PDF. El PDF Shuffler en particular nos permite mantener otros datos embebidos dentro del PDF, como por ejemplo el reconocimiento óptico de caracteres (OCR) que le hayamos hecho a nuestras imágenes.
Pero sin dudas, la forma más fácil de armar una separata de artículos es usando nuestro propio lector de PDFs. Para ello, lo que tenemos que hacer es abrir nuestro documento que procesamos con el gImageReader para que tenga OCR, y seleccionamos la opción «Imprimir»:
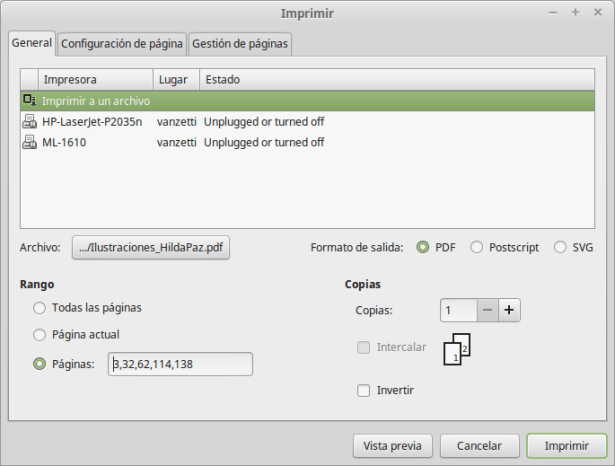
Ahí seleccionamos la opción «Imprimir a un archivo» y colocamos la selección de páginas que corresponda para el artículo (por ejemplo, 3,5-10), y en el nombre de archivo colocamos el que queramos usar. Para esto, lo más práctico es empezarlos siempre con un número, ordenado secuencialmente (01, 02, 03, 04, 05, 06… y así sucesivamente), y de esa forma nos evitamos tener que rearmar el índice de artículos cuando armemos la página del blog para cada número.
En el caso de la Cuadernos, lo que nosotros estuvimos haciendo fue establecer primero los rangos de páginas. Así, analizábamos el PDF, construíamos el índice analítico, luego armábamos el rango de páginas (3,5-10, 3,11-23, etc.), e imprimíamos para cada artículo. Hay que tener en cuenta que al subir los artículos a WordPress, WordPress no es sensible a las mayúsculas y los pasa a todos los nombres a minúscula. Lo mejor entonces es no preocuparse por ponerle mayúsculas a los nombres.
Un dato importante a tener en cuenta es que en algunos casos nuestras páginas digitales quedan más pequeñas que el tamaño de impresión predeterminado (por ejemplo, la Cuadernos es un poco más chica que una hoja A4). En esos casos, lo que debemos hacer es dirigirnos a la pestaña de «Configuración de página» y seleccionar un tamaño personalizado o bien un tamaño que se adapte a nuestro formato de impresión.
2. Cómo mejorar la tipografía original de un libro
La Cuadernos es una revista muy interesante pero también es una revista muy artesanal. Así, no fue infrecuente ver imágenes como esta, con tipografías en este estado:

Estas imágenes no tienen arreglo en la captura, ya que lo que tenemos es un original «deficiente» que es imposible de arreglar. Cuando lo pasemos en el ScanTailor, ya sabemos que el resultado se va a ver mal por más que tengamos una de las mejores cámaras de las disponibles en el mercado. Para este tipo de tipografías, ScanTailor nos ofrece una solución ideal: engrosar la tipografía. ¿Cómo lo hacemos?
En el paso final de ScanTailor, cuando ya estamos seleccionando la salida, vamos a la opción «Modo»:

Ahí vemos que nos da la opción «Más fino – Más grueso». En el caso de la imagen está parado en «0», eso quiere decir que tiene el valor de grosor «por defecto» de la imagen. Para una imagen de estas características, vamos a mover el cursor hasta el punto máximo (50) hacia la opción «Más grueso». Eso nos va devolver finalmente una imagen como esta:

Por supuesto, una de las primeras cosas a notar es que a medida que aumentamos el grosor de la tipografía, también aumentamos el «ruido» de la imagen. Para evitar ese efecto, lo que hacemos es seleccionar el pincelito más grueso en la opción de «Eliminar manchas» del ScanTailor, que nos va a reducir el nivel de ruido (esas manchas que se ven atrás de la letra). En todos los casos, si queremos que los dos procesos se apliquen a todas las páginas, lo único que tenemos que hacer es entrar a la opción «Aplicar a» y seleccionar «Todas las páginas».
¿Por qué es importante hacer este paso en tipografías como esta? Porque malos caracteres = peores resultados para el OCR. Simple.
3. Armar un índice de autores en WordPress
Este paso, al igual que los anteriores, es bastante simple, pero en general son esos truquitos que si no los tenemos muy presentes, son difíciles de hacer. Para armar esto lo único que tenemos que hacer es saber un poco de HTML. Cada letra del alfabeto tiene un encabezado con una etiqueta asignada (a la D la etiquetamos como la «D», por ejemplo), y luego lo que hacemos es linkear internamente. Para eso, tenemos que salir de la opción «Visual» de WordPress e ir a la parte que dice «HTML» y allí pegamos un código como este:
<a href=»#A»>A</a> donde para «A» vamos a crear este código: <h3 id=»A»>A</h3>. En este caso, «id» es la etiqueta / nombre para nuestra letra, y «h3» es igual a heading. Abajo de esa A con nombre ponemos todos los autores que queramos y después podemos navegar por el índice de autores alfabético a nuestro gusto. Repetimos esa operación con todas las letras del abecedario para las que tengamos autores, ¡y eso es todo!
Otra opción para entender mejor cómo funciona este código es pararse en el índice de autores, hacer click derecho sobre cualquier parte de la página (que no tenga un link, claro), y apretar la opción «Ver código fuente». Funciona tanto en Mozilla Firefox como en Chrome. Ahí pueden ver el código con el que está construido el índice y replicarlo.
Eso es todo, cuando encaremos la digitalización de la Revista Tsé-Tsé (otro proyecto traído por Matías Raia), vamos a explicar algunos detalles más, por ejemplo, cómo lidiar con páginas que tienen imágenes detrás del texto (algo que en la Cuadernos del Sur no prestamos demasiada atención, ya que esto sólo apareció en los últimos números) y cómo trabajar con tapas a color que no hayamos podido digitalizar con toda la calidad que nos hubiera gustado. Por ahora, esto es todo. ¡Buena lectura!
